

27·
2 months agoThat’s a nice unintended pun for a publisher named “404media” to talk about removed stuff being backed up
🇬🇧 | 24yo French web dev & tech enthusiast
🇫🇷 | Développeur web Limougeaud de 24 ans passionné par l’informatique
Main fediverse account (Mastodon) : mamot.fr/@KaKi87
Blog (Lemmy) : blog.kaki87.net
Formerly @KaKi87@sh.itjust.works, moved because of Cloudflare.
That’s a nice unintended pun for a publisher named “404media” to talk about removed stuff being backed up
Meta also argued that the BitTorrent sharing was a necessity to get the valuable (but pirated) data.
Actually that’s not true, they could have done hit-and-run, not that it helps anything though.
The company also stresses that the data helped establish U.S. global leadership in AI.
Just like the data helps establish much needed universal access to education and entertainment.
But of course, the argument is only relevant when it goes in favor of the rich people.
Oh, indeed.
However, if you click switch the “hide links” dropdown to “show links”, there’s a bunch of forum links appearing, if you can create or already have an account on one of those then you could download there, or you could download elsewhere while making sure the hashes match.
There’s a link on fmhy.net
It might be, yes : https://github.com/aeharding/voyager/blob/main/src/routes/pages/shared/CommentsPage.tsx#L41
As mentioned by @cypherpunks@lemmy.ml, the solution is to add type_=All in query parameters.
From the Voyager app’s source code, it seems like the value is undefined by default.
I think replacing this by All could fix the issue. But, I have no experience in that app’s dev stack, so I can’t be sure.
Therefore, I’d suggest submitting a GitHub issue showing 2 screenshots : of the same post, one on Voyager, the other one on another app, where the former shows less comments than the latter. Indicate that replacing undefined with All might fix the issue.
If the maintainer(s) reproduce and confirm, they’ll push the fix.
If I was more confident, I’d directly make a PR, but I’m not.
Interesting, thanks !
Thanks.
Now, why isn’t that required for an older post ?
For example : https://lemmy.world/api/v3/comment/list?post_id=5&sort=Old
Go to the admin page in the lemmy UI and turn on federation. If you selected “Allowlist” or “Blacklist”, select “Open” as the federation mode.
All I see is a “Federation enabled” checkbox that is checked, an “allowed instances” list that is empty, a “blocked instances” list that is empty as well, and a “federation debug mode” checkbox that is unchecked.
I don’t see “allowlist”, “blocklist” or “federation mode”.
Thanks
Check the logs and config.
What should I be looking for ?
How to fix this though ?

Willing to give this a go.
Alright, don’t hesitate to ask questions if you have any and request help if you need any
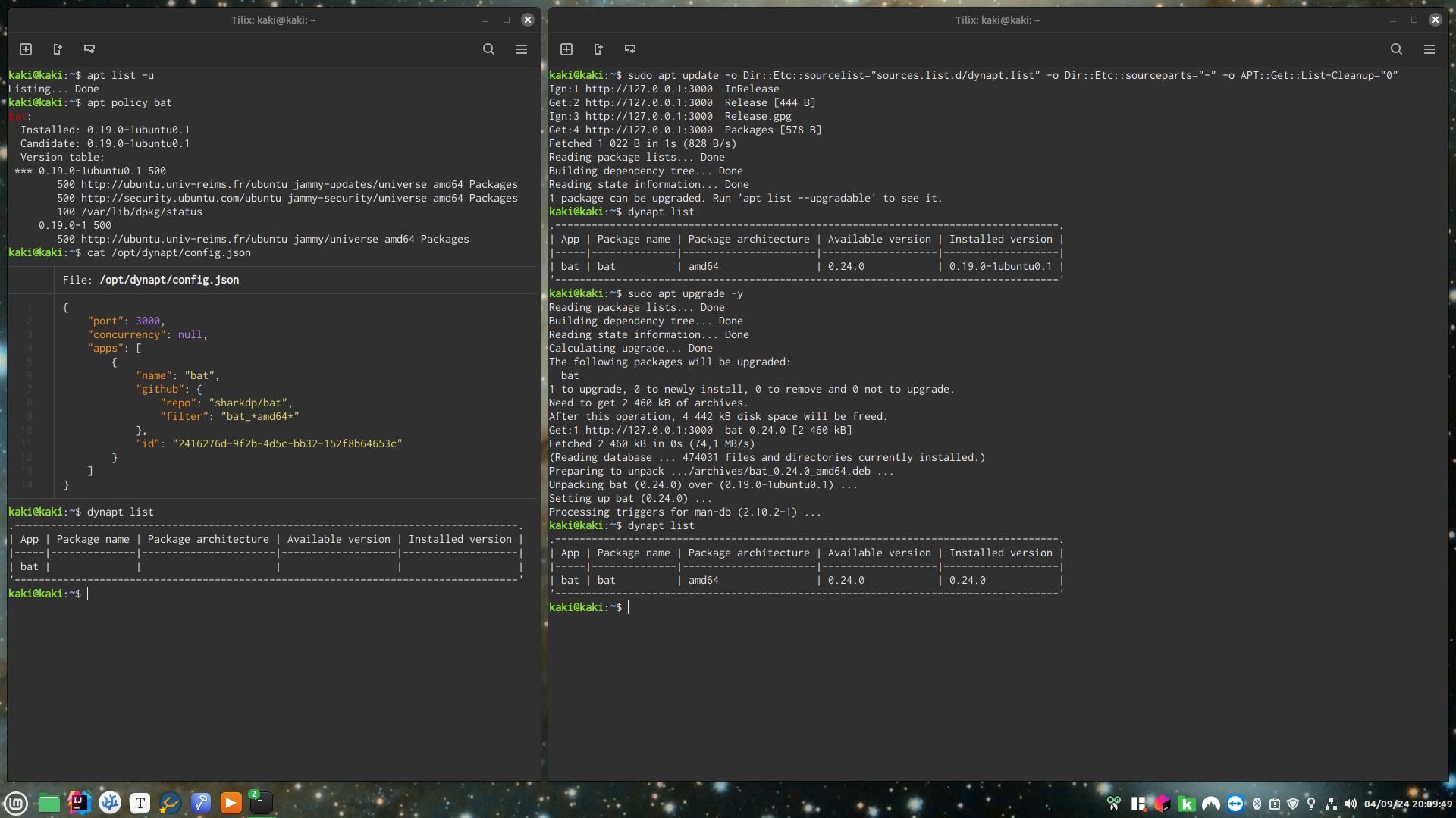
My go-to for getting non-repo debs automatically has been deb-get
Yes, I mentioned it in the Differences with deb-get & AM section of my tutorial.
it seems to go long periods of time between PR merges and releases (which includes adding new software)
Yeah, I could reiterate in that section that my app allows the user to add apps themselves.
I didn’t say it was more secure, I said it’s about the same.
You said automation breeds laziness (by design, to an extent) and lazy end users tend to shoot themselves in the foot.
So, my question is : what part of automating download of DEBs from a specific source can be shooting oneself in the foot compared to doing the same thing manually every time ?
you should legally protect yourself
The MIT license will take care of that.
Also, to force the user to accept and acknowledge that the software they are installing using this tool is not verified to be safe is inducing fear and/or guilt, therefore is bad UX, I’m not doing that.
It’s more functional than object-oriented and I read the former better than the latter. 😅
You understand perfectly.
How is the manual step more secure though ?
What does the user do before downloading a DEB that makes that gap between manual and automated ?
I’d be willing to try and reproduce that, but I don’t see anything.
It doesn’t, that’s provided by Cortile.
My point is that I’m working a solution for end users.
The solutions you’re offering are not user-friendly.
I don’t care.
{kind=link}
Maybe direct download makes money, as they often limit download count and speed to promote paid subscriptions, which a visitor only needs if someone uploaded something they need, so the uploader gets some money back, I guess. And for the others, there’s still ad revenue
Torrent links can still be found on pages full of ads, but still, once you got the file or the magnet link, you don’t need to be on that site anymore.